




训练一个AI大模型需要多少钱?OpenAI CEO山姆·奥特曼曾表示,GPT-4的训练成本大约1亿美元(约合人民币7.3亿元),未来训练大模型的成本将高于10亿美元。尚未完成训练的GPT-5大模型,为时约半年的一轮训练就消耗了大约5亿美元,可见AI公司的支出成本有多高。
然而在AI行业却有一个异类,被广大网友奉为“AI行业的拼多多”,这家公司就是DeepSeek(深度求索),网传其大模型训练成本压缩到极致,最新推出的DeepSeek-V3大模型训练成本仅为557.6万美元(约合人民币4070万元),大概是GPT-4的二十分之一,总计约消耗了278.8万个GPU小时,参数为6710亿,其中激活参数为370亿。
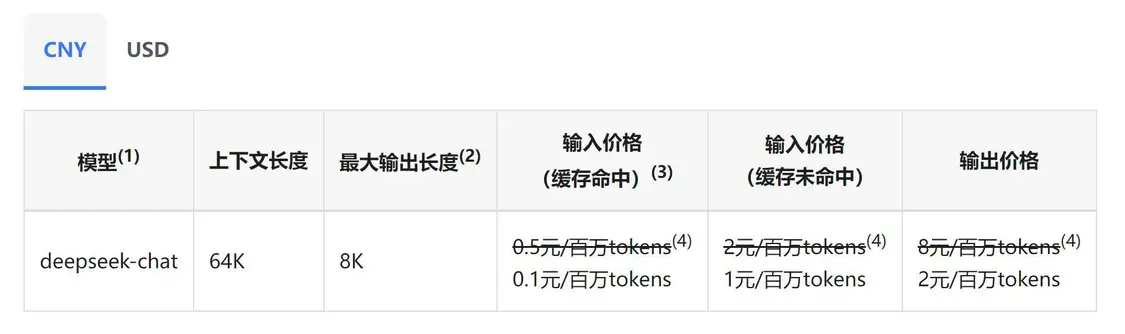
DeepSeek官网的价格表示显示,缓存命中输入价格仅为0.1元/百万tokens,缓冲未命中输入价格为1元/百万tokens,输出价格则为2元/百万tokens,在诸多AI大模型中属于最低的一档。(注明:1token约等于1.5个汉字或3个英文字母)
(图源:DeepSeek截图)
豆包、通义千问等AI大模型,能力较低的版本差不多也是这个价格,但性能较强的大模型如Doubao-pro-128k,输入价格5元/百万tokens,输出价格为9元/百万tokens,Kimi的moonshot-v1-128k输出价格更是高达60元/百万tokens。(注明:数据来自AI公司官方)

(图源:雷科技制作)
DeepSeek-V3超低的训练成本和最低一档的输入、输出价格,令人不禁疑惑,到底是其他AI公司资源利用率太差,还是DeepSeek技术实力太强,抑或DeepSeek-V3的能力是吹的?
好在,尽管DeepSeek-V3的大模型主打开源和API接口使用,但也为用户准备了可以便捷使用的网页版。只要对其测试一番,对比与主流大语言模型的差距,我们就能获知DeepSeek的真正实力。
DeepSeek-V3实测,结果令人惊讶
DeepSeek页面极为简洁,主框仅有深度思考、联网搜索、上传文件、发送四个按钮。如果不打开联网搜索功能,将无法搜索网上相关的信息,只能当作本地大模型使用,且深度思考和联网搜索无法同时开启,但依然需要 电脑联网将问题发送给DeepSeek。
针对DeepSeek-V3,小雷准备了四轮测试,包括通用问答、内容总结、专业数学题、金融知识问答,部分测试还将与豆包、Kimi等大语言模型进行对比,以便于更直观地观察DeepSeek-V3的能力。
一、常规问答:简短整洁、可读性高。
作为一名科技编辑,小雷每天都会向AI询问“今天科技圈有什么新闻”,让AI大模型帮助我快速收集新闻,绝大多数大模型也能够轻松胜任。于是,小雷将其作为第一轮测试题目。
DeepSeek为我寻找了10条新闻,新闻之间用分割线划分,视觉上更加清晰明了。每一段新闻的末尾,还会提供可一键直达的网页链接。该项目的测试中,DeepSeek的亮点在于,新闻的总结简洁且突出了重点,所收集的内容也不局限于国内平台,部分消息来自海外新闻媒体,点击链接可直达海外的新闻网站。有趣的是,DeepSeek还找到了自己的“黑料”,DeepSeek-V3大模型会称自己是ChatGPT,山姆·奥特曼发文回应,认为原因是数据污染。

(图源:DeepSeek截图)
小雷用豆包和Kimi收集新闻时,豆包回复的内容文字太多,内容不够简洁清晰,Kimi则过于精简,新闻的总结基本只有一句话。
随后小雷还让AI推荐几首古典音乐,在未联网的状态下,DeepSeek依然可以准确回答我的问题,只是所有内容全部变成了英文。而切换至联网模式后,再次提问相同的问题,回答的内容则又变成了中文。


